

The development of new technologies is shaping the growth of cities in many ways. Among these, the Internet of Things (IoT), Artificial Intelligence (AI), the high-resolution global positioning system (GPS), big data and new building materials and techniques are expected to transform cities’ core functioning elements, affecting all aspects of our lives (European Commission). When technology is combined with the growing availability of open data, new possibilities emerge to develop a novel understanding of the urban fabric and use.
Deep learning algorithms are a subset of machine learning algorithms, which process and combine their input in ever growing abstractions to obtain meaningful outputs. These are of particular interest in the field of computer vision, enabling the manipulation of large datasets in an automatic way. In the past years, the rising availability of deep learning techniques lead to new frontiers in the automatic understanding of images and estimating the number of objects within an image. In particular, deep learning methods obtained state-of-the-art results for image classification, object detection and instance/semantic segmentation tasks. Furthermore, in the past years, the availability of pre-trained weights for deep learning algorithms has grown.
This project focuses on the analysis of pre-trained deep learning models for object detection, image segmentation and crowd counting. The first two aim to recognize objects and locate them in an image, outputting their bounding boxes or shape masks; the latter aims to estimate the number of people.
The initial purpose was to assess their flaws and potentials given a dataset of images of Corso Buenos Aires, a well-known shopping street in Milan. First, a subset of images was selected, these represent different moments of the year and are used as a means of assessment for the performance of the models. The second goal was to investigate the use of the street for a year period. Thus, the best performing algorithms were used to perform an analysis of the use of the street from September 2019 until September 2020, with a focus on the Covid-19 pandemic lockdown period.
Dataset description
The dataset for the project is a collection of images of Corso Buenos Aires, Milano (MilanoCam.it). These images depict the street with a strong perspective view, showing the flow of vehicles and people from piazza Lima to porta Venezia. The dataset includes images taken at a one hourtime intervals, every day of the year. Thus, different lighting and weather conditions are illustrated. Furthermore, due to the camera position and orientation, objects and people seem highly close to each other and their dimension in the scene decreases rapidly. In order to limit the consequences of this factor, the images were cropped to show the first block of the street only.
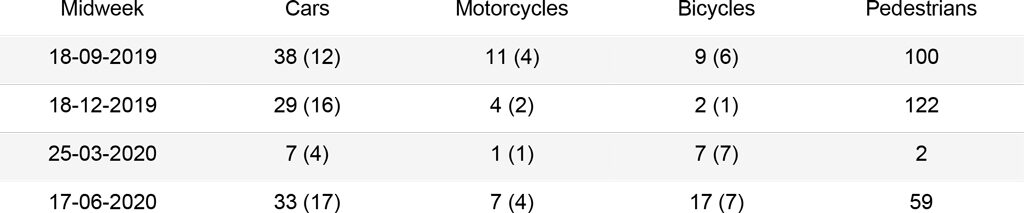
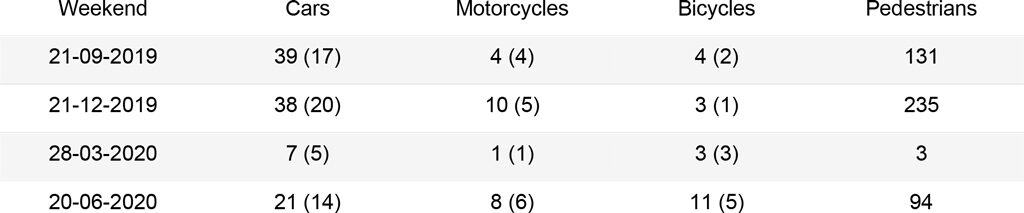
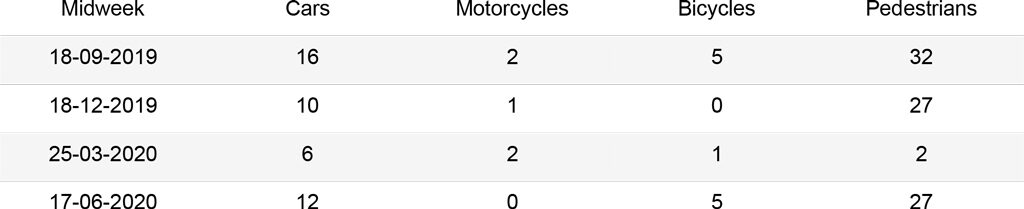
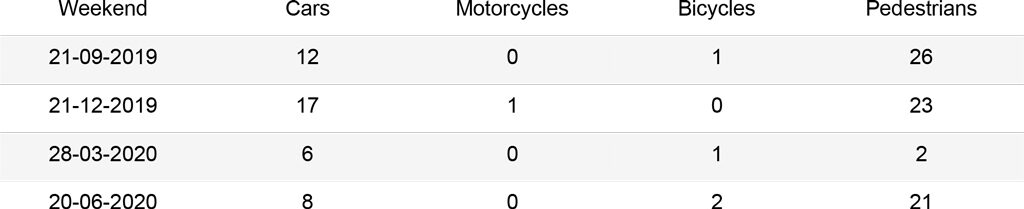
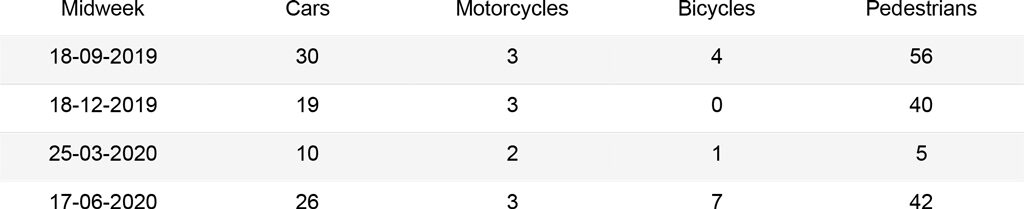
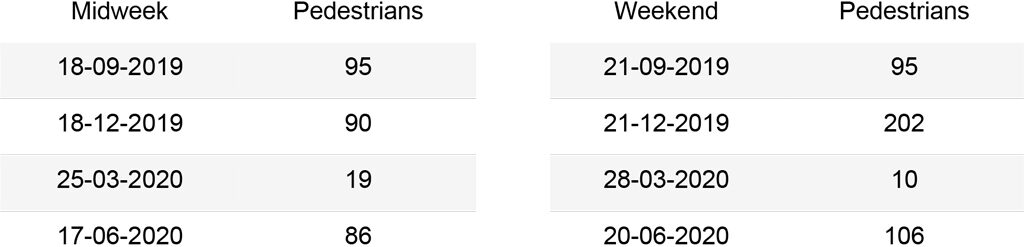
The first analysis was carried out on a set of 16 images that can be grouped as follows: two images for each season of the year (September, December, March, June), which represent a midweek day and a weekend day. For the midweek day, the images are taken at 19:00, when most people leave their offices. Instead for the weekend day, images are taken at 17:00, when the street is busy for evening shopping. The second analysis was carried out on a subset of 367 images, from September 1st, 2019 to September 1st, 2020, each taken at 19:00. These should outline the trends of the street use during different seasons and point to the main issues in the algorithms.

Methodology
This research is divided in two core steps. In the first one, a set of algorithms with pre-trained weights were selected on the basis of their popularity and tested on the dataset. The results were then measured against the manual counts performed on each image. The goal was to define the usability of these models out-of-the-box, for the given dataset.
In the second step, the analysis of the images for a year-long period was carried out. The inference on the images was first automated, then the derived counts were aggregated into plots. The initial focus was on the performance of the algorithms with respect to weather and light conditions as well as business of the street. Finally, the study aimed to identify the patterns in the street use every day at 19:00, the moment when people leave their offices, with particular attention to the Covid-19 lockdown period.
Step 1
Manual count
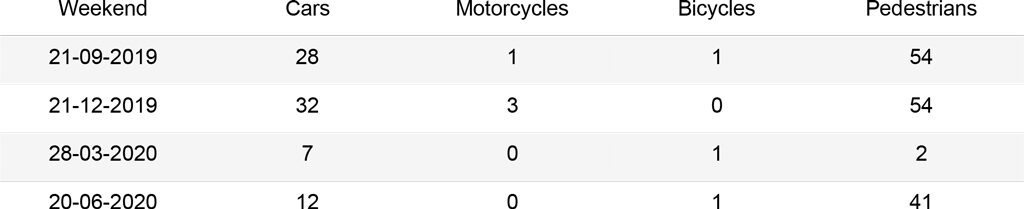
In order to obtain meaningful insights and determine the accuracy of the algorithms, a manual count was performed on the set of 16 images to quantify cars, motorcycles, bicycles and pedestrians. These should be then used as a mean of comparison to assess the best performing algorithm.
Object detection
Object detection aims to detect instances of semantic objects belonging to a certain class and their location in an image. The output of these algorithms are the bounding boxes of each object and their class labels.
Within this research, two object detection models were tested, namely Faster R-CNN (Region-based Convolutional Neural Network) and YOLOv3 (You Only Look Once). Faster R-CNN belongs to the group of region based convolutional neural networks. It consists of two modules, a separate Convolution Neural Network (CNN) for region proposals and a Fast-CNN module, made by a RoI (Region of Interest) layer and a fully connected layer, for extracting features and outputting the bounding boxes and classes of each instance.
YOLO is a group of algorithms that uses a single CNN for predicting bounding boxes and their classes’ probabilities, reducing the computing time to obtain real time predictions. Here, the image is split in a regular grid; each cell is responsible for the prediction of bounding boxes and their confidence and is mapped to a class probability. These are finally combined to obtain the final output. In this research, YOLOv3 was tested.
Both models were trained on the COCO dataset, which represents 80 common objects, including cars, motorcycles, bicycles and people. For Faster R-CNN, the implementation made available by Tensorflow Hub (tf2_object_detection) was customized to take as input the desired images; instead for YOLOv3 the cvlib library was used, following Object detection with less than 10 lines of code using python.
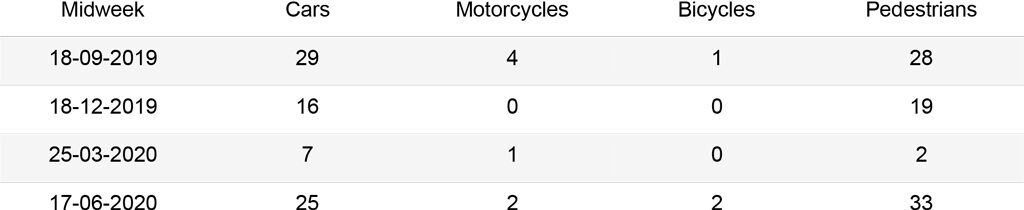
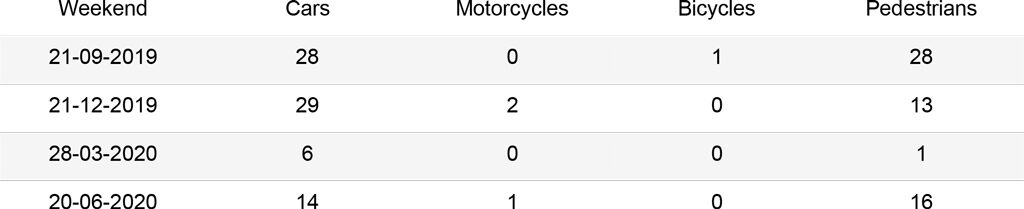
Given the chosen dataset, YOLO3 seems to perform better, especially for the cars’ class. Both models underestimate the number of people in the image; this is due to the strong perspective in the image, where people and objects appear highly congested.
YOLOv3 – COCO

Corso Buenos Aires, 18-09-2019, YOLOv3
Faster R-CNN Inception ResNet152 V1 1024×1024 – COCO
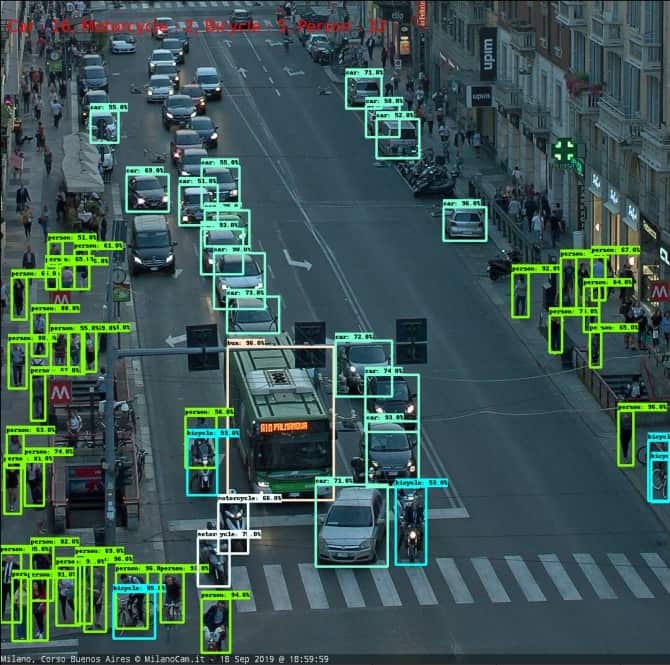
Instance segmentation
Similar to object detection, instance segmentation methods identify and locate objects within an image. Additionally, these algorithms output a segmentation mask outlining the shape of the object.
One instance segmentation algorithm was tested in this research, Mask R-CNN (Mask Region-based Convolutional Neural Network), with pre-trained weights on the COCO dataset. Mask R-CNN is an extension of Faster R-CNN. In addition to Faster R-CNN, this algorithm implements IoU (Intersection over Union) based method to validate the predicted RoI (Region of Interest), then the bonding boxes are fed into a mask classifier consisting of two CNNs.
As it can be seen in the results, this algorithm performs better than the object detection ones for the given images. In fact, it recognizes more car, bicycles and motorbikes instances. Additionally, it is able to detect more people even in congested environments. However, the algorithm is more prone to detect false positives within an image.
Mask R-CNN – COCO

Crowd counting
Crowd counting consists of a group of methods for estimating the number of people in an image. Within this research, the CSRNet (Congested Scene Recognition) algorithm was tested, with the aim to better identify people in cluttered environments.
CSRNet is a crowd counting approach based on a CNN for density estimation. It consists of two modules, a CNN for features extraction and a dilated CNN to enlarge the receptive field and thus learn from a larger portion of the image. In this project, a pre-trained model on the ShanghaiTech dataset was implemented, following (Size.AI). The dataset consists of a set images representing mostly large crowds in Shanghai and in random cities.
Compared to the object detection and segmentation methods, crowd counting predicts a much higher number of people in each image, obtaining promising results for highly congested scenes. As the algorithm was not developed for sparse crowds, the margin of error increases for scarcely populated images.
CSRNet – ShanghaiTech

Analysis
Different methods lead to slightly different results for the same images, usually underestimating the total number of objects. YOLOv3 and Faster R-CNN were implemented with the goal to detect objects in real time, outputting their bounding boxes. Thus, these methods can work best for videos, where objects missed in a scene can be identified in the next frame.
Instead, Mask R-CNN was implemented to work on images and refines the bounding boxes predictions with an additional validation layer. For this reason, this algorithm identifies a higher number of objects, with a small increase in false positive detections only.
Object detection and instance segmentation algorithms are affected by occlusions in the scene. In fact, these algorithms are trained to recognize the shapes of objects, which are hardly identifiable when they overlap. This is a disadvantage in the images of Corso Buenos Aires, where the strong perspective view prevents the algorithm from distinguishing many of the instances. In particular, this fact challenges the quantification of pedestrians and bicycles.
These instances have a smaller size than the others and are thus represented by only a few pixels. For this reason, pedestrians can be better recognized with a crowd counting method. Furthermore, parked instances appear close to each other, as bicycles and motorcycles.
For this reason, higher differences between manual counts and algorithms’ results can be registered for these objects.
Another factor that influenced the results is the level of light and the weather in the images. In fact, during night times it is harder to recognize objects, furthermore, cars’ headlights create bright spots which increase the difficulty in understanding the scene. When this factor is combined with puddles’ reflections, results are strongly worsened in accuracy.
The graphs below summarize the comparison between the different methods for each kind of object. The Cars graph shows how Mask R-CNN and YOLOv3 output similar results, while Faster R-CNN hardly recognizes cars queuing at the red light. The Motorcycles and Bicycles graphs display that Mask R-CNN identifies instances more often than the other algorithms. In fact, it recognizes parked objects. Moreover, during days in which the street is empty (25-03, 28-03), small instances belonging to the street lights are counted as people or cars with the Mask R-CNN algorithm, affecting the results. Finally, the People graph clearly depicts how object recognition and instance segmentation algorithms are not suited for congested scenes. Furthermore, it shows that CSRNet outputs reliable results, with a higher accuracy when the number of people in the image increases.
Corso Buenos Aires – Cars:
Corso Buenos Aires – Motorcycles:
Corso Buenos Aires – Bicycles:
Corso Buenos Aires – People:
Step 2
A one year analysis
After testing different algorithms and understanding their potential, two methods, Mask R-CNN and CSRNet, were selected to extract information on a year-long basis. The first graph plots the number of cars, motorcycles, bicycles and pedestrians computed with Mask R-CNN for one picture a day at 19 over the time period of one year, September 2019 – September 2020. The second graph shows the comparison between the number of pedestrians computed with the same method and with the CSRNet algorithm for crowd counting.
Both graphs outline the immediate consequences for street use in the period of March 2020, after the Covid-19 lockdown was in place in Italy. Furthermore, they show the rapid increase in traffic after the “Fase 2” begin, in May 2020. The Mask R-CNN graph also depicts how cars are the most used vehicles in corso Buenos Aires.
The People graph shows how the instance segmentation method only detects a maximum of around 50 people for each image. Instead, the crowd counting method is able to estimate with better accuracy the density of the crowds, especially for highly congested scenes. During the lockdown period between the middle of March and the beginning of May, it can be seen how the number of detected pedestrians is too high if compared to the instance segmentation method.
Corso Buenos Aires – one year:
Corso Buenos Aires – People one year:
Conclusions and future research
This research aimed to study different methods to identify and count objects in images. The goal was to understand the potential of each method, with available pre-trained weights. Then, the purpose was to analyse the street use of Corso Buenos Aires for a year-long period.
The study highlighted that the algorithms work well for car instances, but present a number of limitations for the other classes of objects. This is due to the characteristics of the images, which may have a strong perspective view, can be dark and not contrasted and present instances which are represented by few pixels.
Furthermore, this is due to the setting of the analysis, in particular the use of pre-trained weights and anchors’ sizes, which represent the typical dimensions of the objects in the image and were not modified in the study. Finally, only a limited number of algorithms were tested for the purpose of the study, thus different outputs could be obtained if other methods were selected.
The results obtained provide valuable insights for future analyses using object detection and image segmentation methods. Firstly, the position and orientation of the camera can influence the outputs greatly.
Images that present a high perspective view are not best suited for detection tasks, where instances of the same class should have a similar dimension throughout the frame and should be visible with little occlusions.
Secondly, the use of pre-trained models without modifications give satisfying results for the images of Corso Buenos Aires only for a reduced portion of the original picture and for bigger instances, such as cars. Modifying the anchors’ sizes could improve the results for smaller objects, however it would not be sufficient to recognize parked bicycles and motorcycles, which are very close to each other. The research highlighted also a range of potential applications for object detection and image segmentation methods. A first example is an analysis on how differential speed limits and the consequent interaction between different types of vehicles within a street can affect safety.
Furthermore, images and videos could be used to track movement patterns of a person or groups of people and understand their behaviour in different context. Behavioural analysis can also be linked to climate-driven route choices, for example, a study of the use of Corso Buenos Aires sidewalks based on the sunlight’s angle.
A final example is represented by the usage of this information and other data from different sources (wi-fi hot spots, mobile and telco data, etc.) to implement innovative predictive models able to replicate and forecast complex pedestrian flow patterns at both urban district and city levels, as implemented in the city of Melbourne.